Table of Contents
Overview
Duplicate code can be hard to find, especially in a large project. But PMD’s Copy/Paste Detector (CPD) can find it for you!
CPD works with Java, JSP, C/C++, C#, Go, Kotlin, Ruby, Swift and many more languages.
It can be used via command-line, or via an Ant task.
It can also be run with Maven by using the cpd-check goal on the Maven PMD Plugin.
Your own language is missing? See how to add it here.
Why should you care about duplicates?
It’s certainly important to know where to get CPD, and how to call it, but it’s worth stepping back for a moment and asking yourself why you should care about this, being the occurrence of duplicate code blocks.
Assuming duplicated blocks of code are supposed to do the same thing, any refactoring, even simple, must be duplicated too – which is unrewarding grunt work, and puts pressure on the developer to find every place in which to perform the refactoring. Automated tools like CPD can help with that to some extent.
However, failure to keep the code in sync may mean automated tools will no longer recognise these blocks as duplicates. This means the task of finding duplicates to keep them in sync when doing subsequent refactorings can no longer be entrusted to an automated tool – adding more burden on the maintainer. Segments of code initially supposed to do the same thing may grow apart undetected upon further refactoring.
Now, if the code may never change in the future, then this is not a problem.
Otherwise, the most viable solution is to not duplicate. If the duplicates are already there, then they should be refactored out. We thus advise developers to use CPD to help remove duplicates, not to help keep duplicates in sync.
Refactoring duplicates
Once you have located some duplicates, several refactoring strategies may apply depending of the scope and extent of the duplication. Here’s a quick summary:
- If the duplication is local to a method or single class:
- Extract a local variable if the duplicated logic is not prohibitively long
- Extract the duplicated logic into a private method
- If the duplication occurs in siblings within a class hierarchy:
- Extract a method and pull it up in the class hierarchy, along with common fields
- Use the Template Method design pattern
- If the duplication occurs consistently in unrelated hierarchies:
- Introduce a common ancestor to those class hierarchies
Novice as much as advanced readers may want to read on on Refactoring Guru for more in-depth strategies, use cases and explanations.
Finding more duplicates
For some languages, additional options are supported. E.g. Java supports --ignore-identifiers. This has the
effect, that all identifiers are replaced with the same placeholder value before the comparing. This helps to
identify structurally identical code that only differs in naming (different class names, different method names,
different parameter names).
There are other similar options: --ignore-annotations, --ignore-literals, --ignore-literal-sequences,
--ignore-sequences, --ignore-usings.
Note that these options are disabled by default (e.g. identifiers are not replaced with the same placeholder value). By default, CPD finds identical duplicates. Using these options, the found duplicates are not anymore exactly identical.
CLI Usage
CLI options reference
| Option | Description | Default | Applies to |
|---|---|---|---|
--minimum-tokens <count> |
Required The minimum token length which should be reported as a duplicate. | |
|
--dir <path>-d <path> |
Path to a source file, or directory containing
source files to analyze. Zip and Jar files are
also supported, if they are specified directly
(archive files found while exploring a directory
are not recursively expanded). This option can
be repeated, and multiple arguments can be
provided to a single occurrence of the option.
One of --dir, --file-list or --uri must be
provided. |
|
|
--file-list <filepath> |
Path to a file containing a list of files to
analyze, one path per line. One of --dir,
--file-list or --uri must be provided. |
|
|
--language <lang>-l <lang> |
The source code language.
See also Supported Languages.
Using |
java |
|
--debug--verbose-D-v |
Debug mode. Prints more log output. See also Logging. | |
|
--encoding <charset>-e <charset> |
Specifies the character set encoding of the source code files PMD is reading.
The valid values are the standard character sets of java.nio.charset.Charset. |
UTF-8 |
|
--skip-duplicate-files |
Ignore multiple copies of files of the same name and length in comparison. | |
|
--exclude <path> |
Files to be excluded from the analysis | |
|
--non-recursive |
Don't scan subdirectories. By default, subdirectories are considered. | |
|
--skip-lexical-errors |
Deprecated Skip files which can't be tokenized due to invalid characters instead of aborting CPD.
By default, CPD analysis is stopped on the first error. This is deprecated. Use --fail-on-error instead. |
|
|
--format <format>-f <format> |
Output format of the analysis report. The available formats are described here. | text |
|
--relativize-paths-with <path>-z <path> |
Path relative to which directories are rendered in the report. This option allows shortening directories in the report; without it, paths are rendered as mentioned in the source directory (option "--dir"). The option can be repeated, in which case the shortest relative path will be used. If the root path is mentioned (e.g. "/" or "C:\\"), then the paths will be rendered as absolute. | |
|
--[no-]fail-on-error |
Specifies whether CPD exits with non-zero status if recoverable errors occurred.
By default CPD exits with status 5 if recoverable errors occurred (whether there are duplications or not).
Disable this option with --no-fail-on-error to exit with 0 instead. In any case, a report with the found duplications will be written. |
|
|
--[no-]fail-on-violation |
Specifies whether CPD exits with non-zero status if violations are found.
By default CPD exits with status 4 if violations are found.
Disable this feature with --no-fail-on-violation to exit with 0 instead and just output the report. |
|
|
--ignore-literals |
Ignore literal values such as numbers and strings when comparing text. By default, literals are not ignored. | |
Java, C++ |
--ignore-literal-sequences |
Ignore sequences of literals such as list initializers. By default, such sequences of literals are not ignored. | |
C#, C++, Lua |
--ignore-identifiers |
Ignore names of classes, methods, variables, constants, etc. when comparing text. By default, identifier names are not ignored. | |
Java, C++ |
--ignore-annotations |
Ignore language annotations (Java) or attributes (C#) when comparing text. By default, annotations are not ignored. | |
C#, Java |
--ignore-sequences |
Ignore sequences of identifier and literals. By default, such sequences are not ignored. | |
C++ |
--ignore-usings |
Ignore using directives in C# when comparing text.
By default, using directives are not ignored. |
|
C# |
--no-skip-blocks |
Do not skip code blocks matched by --skip-blocks-pattern |
|
C++ |
--skip-blocks-pattern |
Pattern to find the blocks to skip. It is a string property and contains of two parts,
separated by |. The first part is the start pattern, the second part is the ending pattern. |
#if 0|#endif |
C++ |
--uri <uri>-u <uri> |
Database URI for sources. One of --dir,
--file-list or --uri must be provided. |
|
PLSQL |
--help-h |
Print help text | |
Examples
Minimum required options: Just give it the minimum duplicate size and the source directory:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/java
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\java
You can also specify the language:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/cpp --language cpp
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\cpp --language cpp
You may wish to check sources that are stored in different directories:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/java --dir src/test/java
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\java --dir src\test\java
There is no limit to the number of --dir, you may add.
You may wish to ignore identifiers so that more duplications are found, that only differ in naming:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/java --ignore-identifiers
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\java --ignore-identifiers
And if you’re checking a C source tree with duplicate files in different architecture directories
you can skip those using --skip-duplicate-files:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/cpp --language cpp --skip-duplicate-files
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\cpp --language cpp --skip-duplicate-files
You can also specify the encoding to use when parsing files:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/java --encoding utf-16le
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\java --encoding utf-16le
You can also specify a report format - here we’re using the XML report:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/java --format xml
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\java --format xml
The default format is a text report, but there are other supported formats
Note that CPD’s memory usage increases linearly with the size of the analyzed source code; you may need to give Java more memory to run it, like this:
~ $ export PMD_JAVA_OPTS=-Xmx512m
~ $ pmd cpd --minimum-tokens 100 --dir src/main/java
C:\> set PMD_JAVA_OPTS=-Xmx512m
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\java
If you specify a source directory but don’t want to scan the sub-directories, you can use the non-recursive option:
~ $ pmd cpd --minimum-tokens 100 --dir src/main/java --non-recursive
C:\> pmd.bat cpd --minimum-tokens 100 --dir src\main\java --non-recursive
Exit status
Please note that if CPD detects duplicated source code, it will exit with status 4 (since 5.0) or 5 (since 7.3.0). This behavior has been introduced to ease CPD integration into scripts or hooks, such as SVN hooks.
| 0 | Everything is fine, no code duplications found and no recoverable errors occurred. |
| 1 | CPD exited with an exception. |
| 2 | Usage error. Command-line parameters are invalid or missing. |
| 4 | At least one code duplication has been detected unless --no-fail-on-violation is set.Since PMD 5.0. |
| 5 | At least one recoverable error has occurred. There might be additionally zero or more duplications detected.
To ignore recoverable errors, use --no-fail-on-error.Since PMD 7.3.0. |
Logging
PMD internally uses slf4j and ships with slf4j-simple as the logging implementation. Logging messages are printed to System.err.
The configuration for slf4j-simple is in the file conf/simplelogger.properties. There you can enable
logging of specific classes if needed. The --debug command line option configures the default log level
to be “debug”.
Supported Languages
- C#
- C/C++
- Coco
- Dart
- EcmaScript (JavaScript)
- Fortran
- Gherkin (Cucumber)
- Go
- Groovy
- Html
- Java
- Jsp
- Julia
- Kotlin
- Lua
- Matlab
- Modelica
- Objective-C
- Perl
- PHP
- PL/SQL
- Python
- Ruby
- Salesforce.com Apex
- Scala
- Swift
- T-SQL
- TypeScript
- Visualforce
- vm (Apache Velocity)
- XML
- POM (Apache Maven)
- XSL
- WSDL
Available report formats
- text : Default format
- xml (and xslt)
- csv
- csv_with_linecount_per_file
- vs
For details, see CPD Report Formats.
Ant task
Andy Glover wrote an Ant task for CPD; here’s how to use it:
<path id="pmd.classpath">
<fileset dir="/home/joe/pmd-bin-7.7.0/lib">
<include name="*.jar"/>
</fileset>
</path>
<taskdef name="cpd" classname="net.sourceforge.pmd.ant.CPDTask" classpathref="pmd.classpath" />
<target name="cpd">
<cpd minimumTokenCount="100" outputFile="/home/tom/cpd.txt">
<fileset dir="/home/tom/tmp/ant">
<include name="**/*.java"/>
</fileset>
</cpd>
</target>
Attribute reference
| Attribute | Description | Default | Applies to |
|---|---|---|---|
minimumtokencount |
Required A positive integer indicating the minimum duplicate size. | |
|
encoding |
The character set encoding (e.g., UTF-8) to use when reading the source code files, but also when
producing the report. A piece of warning, even if you set properly the encoding value,
let's say to UTF-8, but you are running CPD encoded with CP1252, you may end up with not UTF-8 file.
Indeed, CPD copy piece of source code in its report directly, therefore, the source files
keep their encoding. If not specified, CPD uses the system default encoding. |
|
|
failOnError |
Whether to fail the build if any errors occurred while processing the files. Since PMD 7.3.0. | true |
|
format |
The format of the report (e.g. csv, text, xml). |
text |
|
ignoreLiterals |
if true, CPD ignores literal value differences when evaluating a duplicate
block. This means that foo=42; and foo=43; will be seen as equivalent. You may want
to run PMD with this option off to start with and then switch it on to see what it turns up. |
false |
Java |
ignoreIdentifiers |
Similar to ignoreLiterals but for identifiers; i.e., variable names, methods names, and so forth. |
false |
Java |
ignoreAnnotations |
Ignore annotations. More and more modern frameworks use annotations on classes and methods, which can be very redundant and trigger CPD matches. With J2EE (CDI, Transaction Handling, etc) and Spring (everything) annotations become very redundant. Often classes or methods have the same 5-6 lines of annotations. This causes false positives. | false |
Java |
ignoreUsings |
Ignore using directives in C#. | false |
C# |
skipDuplicateFiles |
Ignore multiple copies of files of the same name and length in comparison. | false |
|
skipLexicalErrors |
Deprecated Skip files which can't be tokenized
due to invalid characters instead of aborting CPD. This parameter is deprecated and
ignored since PMD 7.3.0. It is now by default true. Use failOnError instead to fail the build. |
true |
|
skipBlocks |
Enables or disabled skipping of blocks like a pre-processor. See also option skipBlocksPattern. | true |
C++ |
skipBlocksPattern |
Configures the pattern, to find the blocks to skip. It is a string property and contains of two parts,
separated by |. The first part is the start pattern, the second part is the ending pattern. |
#if 0|#endif |
C++ |
language |
Flag to select the appropriate language (e.g. c, cpp, cs, java, jsp, php, ruby, fortran
ecmascript, and plsql). |
java |
|
outputfile |
The destination file for the report. If not specified the console will be used instead. | |
Also, you can get verbose output from this task by running ant with the -v flag; i.e.:
ant -v -f mybuildfile.xml cpd
Also, you can get an HTML report from CPD by using the XSLT script in pmd/etc/xslt/cpdhtml.xslt. Just run the CPD task as usual and right after it invoke the Ant XSLT script like this:
<xslt in="cpd.xml" style="etc/xslt/cpdhtml.xslt" out="cpd.html" />
See section “xslt” in CPD Report Formats for more examples.
GUI
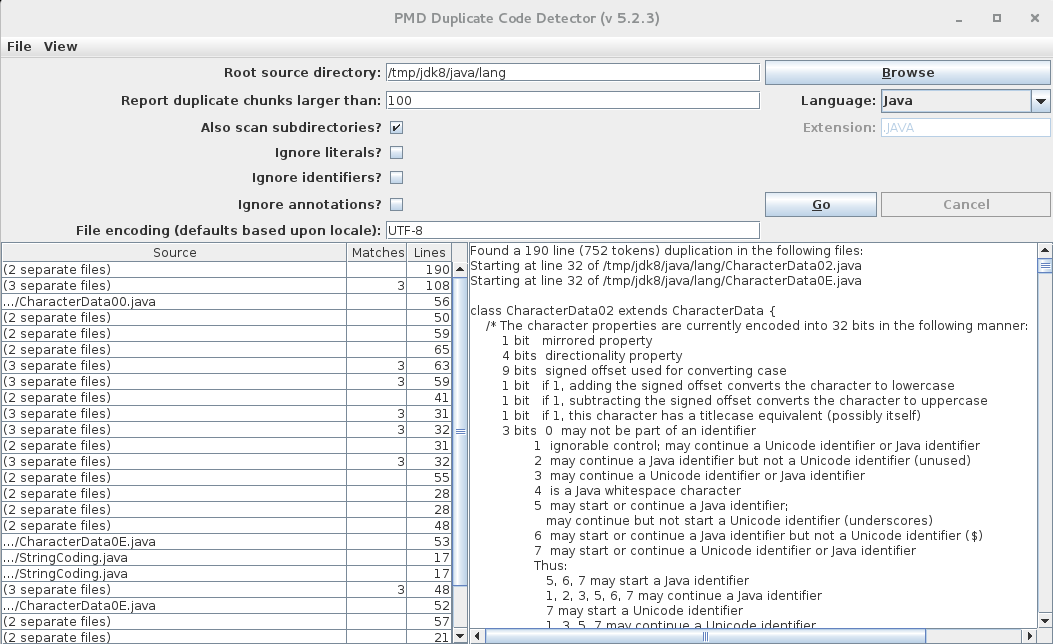
CPD also comes with a simple GUI. You can start it through the unified CLI interface provided in the bin folder:
~ $ pmd cpd-gui
C:\> pmd.bat cpd-gui
Here’s a screenshot of CPD after running on the JDK 8 java.lang package:
Suppression
Arbitrary blocks of code can be ignored through comments on Java, C/C++, Dart, Go, Groovy, Javascript,
Kotlin, Lua, Matlab, Objective-C, PL/SQL, Python, Scala, Swift and C# by including the keywords CPD-OFF and CPD-ON.
public Object someParameterizedFactoryMethod(int x) throws Exception {
// some unignored code
// tell cpd to start ignoring code - CPD-OFF
// mission critical code, manually loop unroll
goDoSomethingAwesome(x + x / 2);
goDoSomethingAwesome(x + x / 2);
goDoSomethingAwesome(x + x / 2);
goDoSomethingAwesome(x + x / 2);
goDoSomethingAwesome(x + x / 2);
goDoSomethingAwesome(x + x / 2);
// resume CPD analysis - CPD-ON
// further code will *not* be ignored
}
Additionally, Java allows to toggle suppression by adding the annotations
@SuppressWarnings("CPD-START") and @SuppressWarnings("CPD-END")
all code within will be ignored by CPD.
This approach however, is limited to the locations were @SuppressWarnings is accepted.
It is legacy and the new comment based approach should be favored.
//enable suppression
@SuppressWarnings("CPD-START")
public Object someParameterizedFactoryMethod(int x) throws Exception {
// any code here will be ignored for the duplication detection
}
//disable suppression
@SuppressWarnings("CPD-END")
public void nextMethod() {
}
Other languages currently have no support to suppress CPD reports. In the future, the comment based approach will be extended to those of them that can support it.
Credits
CPD has been through three major incarnations:
-
First we wrote it using a variant of Michael Wise’s Greedy String Tiling algorithm (our variant is described here).
-
Then it was completely rewritten by Brian Ewins using the Burrows-Wheeler transform.
-
Finally, it was rewritten by Steve Hawkins to use the Karp-Rabin string matching algorithm.